Using MaPLe to Solve the One Billion Row Challenge
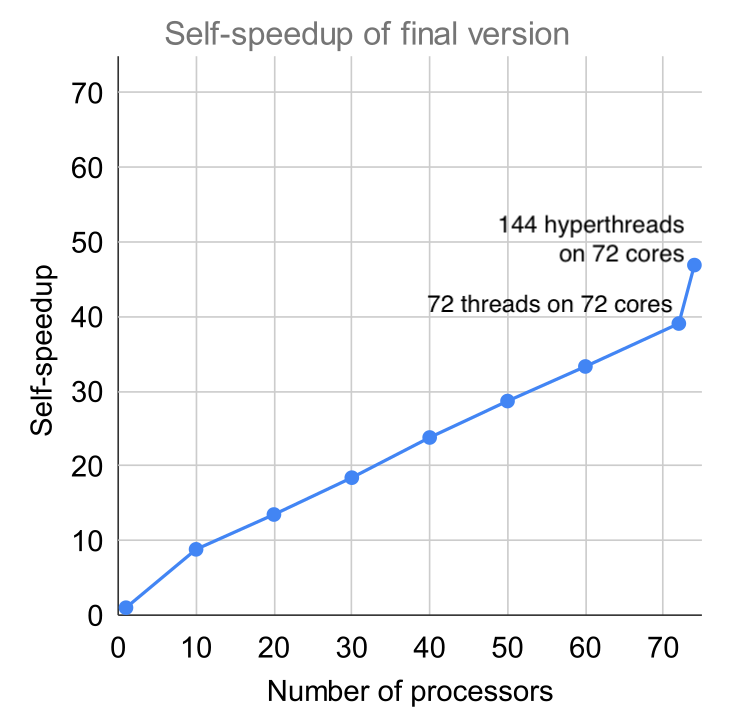
The One Billion Row Challenge took off recently, and I thought it would be fun to try solving it using MaPLe (MPL for short). The MPL language is a parallel functional language, with excellent scalability on multicore machines. I have access to a 72-core (144 hyperthreaded) multicore server, so let’s see how fast we can get on that machine.
My code is
available here: mpl-1brc. It was
pretty quick to throw together an initial working implementation. Then,
to get good performance, I worked through four key optimizations.
Altogether, these optimizations yielded 10x improvement
over my initial code.
Currently, I’m getting just about 2.3 seconds end-to-end on 72 cores (144 hyperthreads), for an input file of one billion rows. It could probably be quite a bit faster with more optimization—I’m using no fancy parsing tricks, no SIMD, and fairly basic hashing. The speed I’m getting at the moment is due largely to MPL’s scalability.

Algorithm
At a high-level, the parallel algorithm I used is pretty straightforward. The idea is to accumulate temperature measurements in a hash table, with station names as keys. We can use a concurrent hash table to allow for insertions and updates to proceed in parallel.
For each station, we need to compute the min, max, and average temperatures. Here’s pseudocode for the algorithm:
- Allocate a hash table \(T\), with strings (station names) as keys, and tuples
\((\ell, h, t, c)\) as values. The tuple is used to store four components for each station:
- \(\ell\): the lowest (min) temperature recorded
- \(h\): the highest (max) temperature recorded
- \(t\): the total (sum) of all temperatures recorded
- \(c\): the count of the number of recorded temperatures
- In parallel, for each entry
<s>;<m>in the input file (station name \(s\), and measurement \(m\)), do the following atomically:- If \(s\) is not yet in \(T\), then insert: \(T[s] := (m, m, m, 1)\)
- Otherwise, read the current value \((\ell, h, t, c) = T[s]\), and update with \(T[s] := (\min(m,\ell), \max(m,h), m+t, c+1)\).
- After all insertions have completed, for each final entry \(s \mapsto (\ell, h, t, c)\) compute the average temperature: \(t/c\).
- Output all results in sorted order in the appropriate format.
Implementation and optimizations
I used four key optimizations to make the implementation faster; altogether, these optimizations yielded 10x improvement over my first implementation, and brought the runtime down to just about 2.3s on 72 cores (144 hyperthreads).
- Don’t allocate any intermediate strings. Instead, use file offsets as keys in the hash table, and compare keys by directly reading from the contents of the file.
- Don’t tokenize, and instead parse on-the-fly in the main loop.
- In my initial implementation, I started with a pass over the file to tokenize it into station names and measurements. This was helpful for getting started, but also resulted in a ~2x slowdown.
- Reduce contention in the hash table by sharding.
- Don’t pre-load the file into an array. Instead,
mmapthe file into memory and then operate directly on the contents this way.- MPL provides support for
mmap-ed files, so this wasn’t too bad. In my code, I use a “file buffer” to load characters from themmap-ed file and then operate locally on the buffer.
- MPL provides support for
Main loop. Here’s what my current main loop looks like. This is very similar to the actual code (link), although I’ve removed some small details and renamed a few things to make it easier to read standalone here.
structure HashTable = ...
structure Buffer = ...
val table = HashTable.make ()
(* `buffer`: a piece of the input file
* `cursor`: current position within the input file
* `stop`: position in the file where we should stop parsing
* requires that `cursor` is at the start of a line, and that `stop` is
* at the end of a line (and that `stop >= cursor`).
*)
fun inner_loop buffer cursor stop =
if cursor >= stop then
()
else
let
(* This is position of the start of an entry. We use this as the key
* in the hash table.
*)
val start = cursor
(* Walk until we see a semicolon, and compute the hash of the station
* name along the way.
*)
val (buffer, cursor, h) = parse_hash_of_station_name buffer cursor
val cursor = cursor + 1 (* get past the ";" *)
(* Walk until we get to the end of the line, and parse the measurement
* along the way.
*)
val (buffer, cursor, m) = parse_measurement buffer cursor
val cursor = cursor + 1 (* get past the newline character *)
val weight = {min = m, max = m, tot = m, count = 1}
in
(* insert into the hash table with:
* key = start
* value = weight
*
* keys in the hash table are compared by reading from the file. So,
* if the same station name appears at two different positions i and j,
* then the hash table will consider keys i and j to be equal.
*
* if multiple weights are inserted for equal keys, then these will
* be automatically combined.
*)
HashTable.insert_and_combine_values
{ table = table
, key = start
, value = weight
, hash = h
}
(* continue at the new position *)
inner_loop buffer cursor stop
end
(* 1 million characters seems like a reasonable chunk of work, and will
* expose plenty of parallelism.
*)
val chunk_size = 1000000
val num_chunks = ceiling_divide file_size chunk_size
(* Main loop: process chunks in parallel. To find the chunk boundaries, we
* stride by the chunk size and find the nearest line boundaries.
*)
val _ = ForkJoin.parfor 1 (0, num_chunks) (fn chunk_i =>
let
val start = find_next_line_start (chunk_i * chunk_size)
val stop = find_next_line_start ((chunk_i + 1) * chunk_size)
(* allocate a fresh buffer for the file *)
val buffer = Buffer.new ...
in
inner_loop buffer start stop
end)
Combining values. The rest of the code defines the hash table, key comparisons, how values are combined, etc. Here’s a snippet for combining values (code link):
(* `atomic_combine_with f (arr, i) x` atomically performs the update:
* a[i] := f(a[i], x)
* we can implement this with a standard compare-and-swap loop.
*)
fun atomic_combine_with (f: 'a * 'a -> 'a) (arr: 'a array, i: int) (x: 'a) =
let
fun loop current =
let
val desired = f (current, x)
in
if desired = current then
()
else
let
val current' =
array_compare_and_swap (arr, i) (current, desired)
in
if current' = current then () else loop current'
end
end
in
loop (Array.sub (arr, i))
end
fun unpack_atomic_combine_into
( {min, max, tot, count}: hash_table_value
, output: int ArraySlice.slice
)
=
let
(* Open up the array slice to see where we should write values.
*
* (This is looking inside the internals of the hash table. The
* array `arr` is used by the hash table to store the values
* associated with each key.)
*
* The values are stored inlined:
* arr[start+0] = min
* arr[start+1] = max
* arr[start+2] = tot
* arr[start+3] = count
*
* We just need to atomically modify each of these components.
*)
val (arr, start, _) = ArraySlice.base output
in
atomic_combine_with Int.min (arr, start) min;
atomic_combine_with Int.max (arr, start + 1) max;
(* we could use `atomic_combine_with` again here, but instead we can
* take advantage of hardware primitives for fetch_and_add which is a
* bit faster.
*)
array_fetch_and_add (arr, start + 2) tot;
array_fetch_and_add (arr, start + 3) count;
end
Could it be even faster?
I think so. MPL doesn’t yet have native support for SIMD (that’s on the TODO list for MPL), but we could use the FFI to call out to a C function to use SIMD/vector instructions for faster parsing, hashing, or other optimizations. I think this could yield a big improvement.
In the mpl-1brc GitHub repo
README, I list a few other ideas for potential improvements. If anyone is
interested in playing around with it, contributions/PRs are welcome!